Classification Algorithms
Classification Algorithms
Unlocking the Power of Categorization
Introduction:
In the vast realm of Machine Learning (ML), classification algorithms shine as indispensable tools for categorizing data and making accurate predictions. Whether it's sorting emails into spam or non-spam, detecting diseases from medical images, or classifying sentiment in social media posts, classification algorithms have proven their worth across diverse domains. In this blog post, we will delve deep into classification algorithms, exploring their underlying principles, popular techniques, evaluation metrics, and real-world applications.
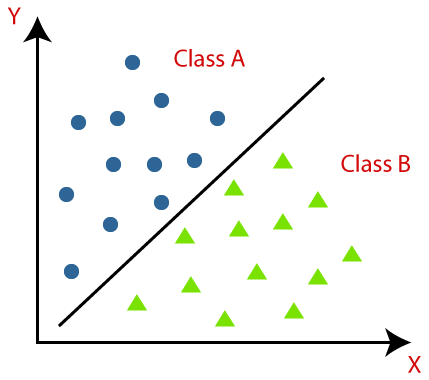
Understanding Classification Algorithms:
Classification algorithms are a fundamental component of supervised learning, focusing on categorizing input data into predefined classes or categories. These algorithms learn patterns from labeled training data and generalize that knowledge to make predictions for new, unseen data instances. The ultimate goal is to build a robust and accurate model that can assign the correct class label to previously unseen instances.
Key Concepts of Classification Algorithms:
Training Data: Classification algorithms require labeled training data, consisting of input samples (features) and their corresponding class labels. The quality, representativeness, and diversity of the training data greatly impact the performance of the classification model.
Feature Extraction: Feature extraction involves identifying informative attributes or characteristics within the input data that aid in accurate classification. Relevant features contribute to the discrimination between classes and help the algorithm learn meaningful patterns.
Decision Boundary: Classification algorithms create decision boundaries in the feature space to separate different classes. These boundaries serve as the basis for assigning class labels to new, unseen data points.
Popular Classification Algorithms:
Logistic Regression: Logistic regression models the relationship between input features and the probability of an instance belonging to a particular class. It is widely used for binary classification tasks and can be extended to handle multi-class problems.
Decision Trees: Decision trees create a tree-like model by splitting data based on different feature values. They are easy to interpret and can handle both categorical and numerical data.
Random Forests: Random forests are an ensemble method that combines multiple decision trees. By aggregating predictions from individual trees, random forests offer improved accuracy and robustness.
Support Vector Machines (SVM): SVMs aim to find an optimal hyperplane that maximally separates classes in the feature space. They are effective for both linear and non-linear classification tasks.
Naive Bayes: Naive Bayes classifiers are probabilistic models that apply Bayes' theorem with the assumption of independence between features. Despite their simplifying assumptions, they often perform well and are computationally efficient.
Evaluation Metrics for Classification:
To assess the performance of classification algorithms, several evaluation metrics are used:
Accuracy: Measures the proportion of correctly classified instances to the total number of instances. It provides a general overview of the model's overall performance.

F1 Score: The F1 score is the harmonic mean of precision and recall, providing a balanced measure of the classifier's performance.

Applications of Classification Algorithms:
Classification algorithms find widespread applications in various domains:
Natural Language Processing (NLP): Sentiment analysis, spam detection, text classification, and topic modeling are some NLP tasks where classification algorithms excel.
Medical Diagnosis: Classification algorithms assist in diagnosing diseases, predicting patient outcomes, and identifying patterns in medical data.
Image and Object Recognition: Classifying images, detecting objects, and identifying features in images are common applications of classification algorithms.
Customer Churn Prediction: By analyzing customer data, classification algorithms can predict the likelihood of customers leaving a service or subscription.
Challenges and Considerations:
While classification algorithms are powerful, certain challenges should be addressed:
Overfitting and Underfitting: Overfitting occurs when a model becomes too complex and performs well on training data but fails to generalize to new data. Underfitting occurs when a model is too simple to capture the underlying patterns. Balancing model complexity is crucial.
Handling Imbalanced Datasets: Imbalanced datasets, where one class dominates the other, can affect model performance. Techniques such as resampling, ensemble methods, and adjusting class weights can help address this challenge.
Feature Selection and Dimensionality: Choosing the right features and managing high-dimensional data can impact the model's performance and computational requirements.
Conclusion:
Classification algorithms form the backbone of supervised learning, enabling accurate categorization and prediction tasks across various domains. By leveraging labeled training data, these algorithms learn patterns and create decision boundaries that facilitate effective classification. Logistic regression, decision trees, random forests, SVMs, and naive Bayes are just a few examples of the rich array of classification algorithms available. Understanding their strengths, evaluation metrics, and considerations is vital for successfully applying these algorithms to real-world problems. As classification algorithms continue to evolve and integrate with other ML techniques, their impact on industries such as NLP, healthcare, image recognition, and customer analytics will undoubtedly grow, opening doors to new possibilities and insights.


Comments
Post a Comment